The field of information technologies is constantly developing and regularly challenges the researchers and practitioners in the field. One of the challenges is Big Data - huge amounts of information that come from various sources, accumulate in information systems and require a huge variety of tools and technologies for their preservation, maintenance, management and retrieval
How can data be retrieved from huge databases efficiently and quickly and without harming users' privacy? The field of information technologies is constantly developing and regularly challenges the researchers and practitioners in the field. One of the challenges is Big Data - huge amounts of information that come from various sources, accumulate in information systems and require a huge variety of tools and technologies for their preservation, maintenance, management and retrieval.
Prof. Eidit Cohen and Prof. Haim Kaplan from the School of Computer Science at Tel Aviv University are developing algorithms that collect, analyze and process information and data. The main ones are designed to solve distance-based problems, which consist of a set of points that are connected to each other and represent different entities. For example, they represent nodes in a road network, users in social networks, songs in digital music services (such as Spotify and YouTube), and queries in search engines (such as Google). Such algorithms are mainly used by technology companies; They need to analyze a lot of information (millions of points and more), and for that they need an efficient and extremely fast algorithmic calculation, which will also protect the personal information of the users.
What is the question? How to develop an efficient and fast algorithmic calculation that also protects personal information?
"Our algorithms help technology companies to analyze and decipher data and extract essential information efficiently and quickly. For example, they can find the most connected and effective groups on social networks or calculate the shortest way to get from one intersection to another, or transport goods. Sometimes these points - such as social groups and nodes - are based on personal information of users, such as location and web searches, and then the calculation must be done without revealing this information," explains Prof. Kaplan.

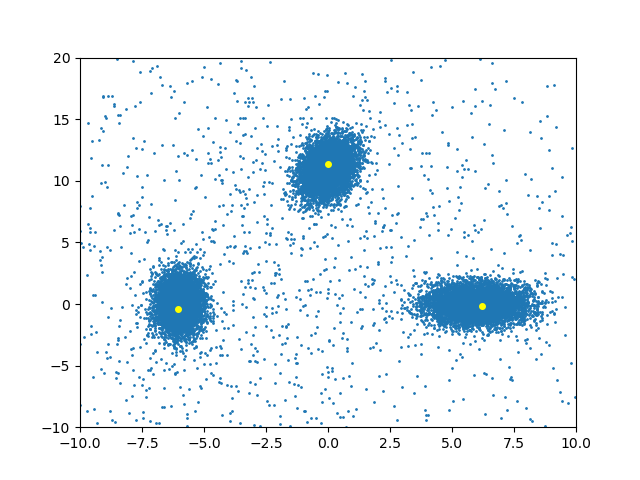
In their latest research, which won a grant from the National Science Foundation, Prof. Cohen and Prof. Kaplan developed algorithms that can solve a variety of distance-based problems, by dividing the points into close groups with similar characteristics. "For example, if we have hundreds of billions of points that represent songs, the algorithms divide them into groups according to their type (the similarity between them, the common characteristics). This way you can quickly identify which group each song belongs to and recommend it to listeners with appropriate preferences. The distance between the points here is actually the similarity between them, it is not physical. The more similar the songs are, the smaller the distance between them," explains Prof. Cohen. Examples of running the algorithm that finds the center of each group in a way that preserves privacy
In order not to reveal personal information of the users (for example, listening to songs with offensive content), the researchers also added elements to the algorithms that preserve differential privacy; This privacy can reveal the general usage pattern of users, but modifies the data each user contributed to the points by adding mathematical noise and thus protects their privacy. That is, the output of the algorithms reveals the groups (overall picture) but not the information behind each and every point, that is, that each user contributed. This is by running the algorithms on the centers (averages) that represent the points and thus the characteristic features of each group. "The algorithms we developed calculate these centers without depending on the strength of the points. They identify abnormal points, which differ in their characteristics from the rest of the points in the group, remove them and only then calculate the centers," says Prof. Kaplan.
The researchers showed that, on the one hand, the algorithms are very efficient, analyzing and calculating data from the groups quickly, and on the other hand, they do not disclose personal information that exists in the points, which as mentioned originates from different users.
The researchers tested the algorithms in several experiments that dealt with different types of information and uses. In all cases, they divided the points into groups according to the degree of similarity between them, calculated their centers, and returned an output that revealed very little information about each specific point (for example, that a user is in a certain group). "We have shown that on the one hand the algorithms are very efficient, analyzing and calculating data from the groups quickly, and on the other hand they do not disclose personal information that exists in the points, which as mentioned originates from different users", Prof. Cohen concludes.
Life itself:
Prof. Eidit Cohen, married + four (ages 25-16), lives in Tel Aviv and California alternately, likes to travel and be with her family, ride a bike, and go on hikes. Haim Kaplan
Prof. Haim Kaplan, married + three (29-year-old twins and 25-year-old twins, computer science students), lives in Hod Hasharon and loves the sea.
