An advanced algorithm makes it possible to quickly retrieve information from the memory of systems such as phones and computers and correct errors

The modern world produces a lot of information at a dizzying pace. How do you store it well in the computer memory and retrieve it quickly when needed? Coding and information theory (information theory) is a mathematical branch that has many applications in technology and science, especially in computer science. It is based on the theory of probability and through it you can develop and test ways to transfer information and save it in computer systems. Thanks to tools from this Torah, modern information technologies have developed and continue to develop, such as cellular communication, data storage systems and communication satellites. "When you put information into a system's memory - such as photos, videos, files and documents - you have to code it, give it a shape, represent it physically. This is so that it can be stored and restored well when needed, without errors appearing in it (such as a blurry image or the inability to open a file)", explains Prof. Yuval Kasuto from the Faculty of Electrical and Computer Engineering at the Technion.
Prof. Kasuto is engaged in the development of information coding methods for modern computing systems such as computers and mobile phones. Coding information means adding bits - data units - into the system's chip. A decoding algorithm which is embedded in the system, reads these bits and with their help corrects errors. Ultimately the goal is to be able to store information in memory and keep it intact. "For example, if you want to increase the storage volume on your mobile phone or computer, you have to change the encoding of the information, so that more bits can fit into the chip. In such a situation, when the density in the chip increases, more errors are created in the information and new ways must be found to maintain it, that is, sufficiently strong codes. For physical reasons, there will always be errors in some bits, but care must be taken to correct them before the information reaches the user," says Prof. Kasuto.
Today, most users need a larger and faster computer memory than before due to the huge amount of information they have to retrieve from the computer quickly. As mentioned, the denser the chip is with data, the higher the risk of errors in the information. According to coding and information theory, effective correction of errors requires a memory structure that is divided into large information storage units, which is the situation in most computer systems today. But large data units slow down access to small data units. Because, the system has to read and correct errors in all of them, and only then can it retrieve the required information and thus its transmission is delayed. That is, the solutions that exist today do not allow quick access to small data units.
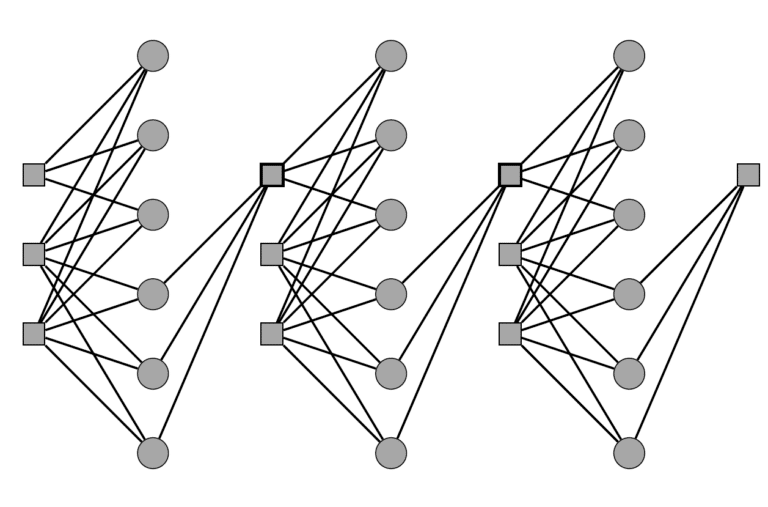
In their latest research, which was awarded a grant from the National Science Foundation, Prof. Kasuto and his team (led by doctoral student Ashad Ram) sought to answer the problem and find a coding method that would allow small units of information to be retrieved quickly from memory. That is, to eliminate the need to read and decode a large unit of information, extract only a small part of it and correct only the errors that occur in it. For this, they added a random access feature to the decoding algorithm. In this way, the small data units can be effectively protected against errors and at the same time can be quickly retrieved when needed. Until now you had to choose between the two options.
The researchers demonstrated the performance of the new algorithm in simulations, on a computer or mobile phone. They generated information, such as images or other files, added errors to some of the bits in its subunits, and then read them through the new algorithm.
The researchers demonstrated the performance of the new algorithm in simulations - that is, they simulated how it would work on a computer or mobile phone; They generated information (such as images or files), added errors to some of the bits in its subunits, and then read them using the new algorithm. Using the algorithm, they encoded a complete unit of information but were able to quickly access the sub-units and showed that the errors could be corrected with high probability. Mathematical description of the new decoding algorithm as a graph divided into interconnected subunits
"We developed an extensive coding theory for the random access feature and showed that the new algorithm, which incorporates it, has a very strong correction power. Using it, it is possible to quickly read and correct errors even in small information subunits without increasing memory consumption. It is particularly effective when the number of errors in the sub-units is small compared to the total of all corrected errors in the large information unit. But we can build a code suitable for any number of errors in the subunits and correct them all with a high probability", Prof. Kasuto concludes.
Today, the researchers continue to develop the algorithm in collaboration with universities and industries abroad so that later they can integrate it into storage devices in computers and mobile phones.
Life itself:
Yuval Kasuto
Prof. Yuval Kasuto, married + three (17, 15, 12), lives in Haifa. likes to run and walk in places near (the wadis of Haifa) and far away.
